For the complete documentation index, see llms.txt.VoxEngine supports a wide variety of Voice AI architectures and components. The right pipeline depends on your priorities -- low latency, interactivity needs, voice choice, and low-level control are some factors to consider.
User↔LLM
Fully integrated Voice AI that often offers the lowest overall latency.
Fastest path | Lowest latencyLLM↔TTS
Realtime LLM for speech input and reasoning, with a separate TTS system for output voice.
More voice choice | Still realtimeSTT↔LLM↔TTS
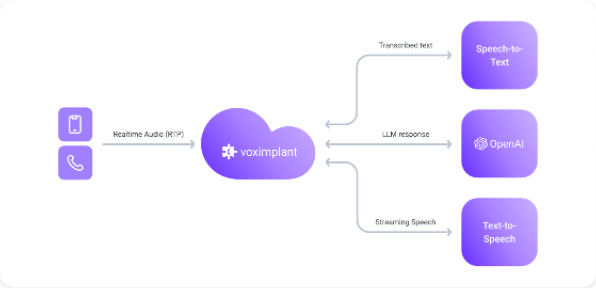
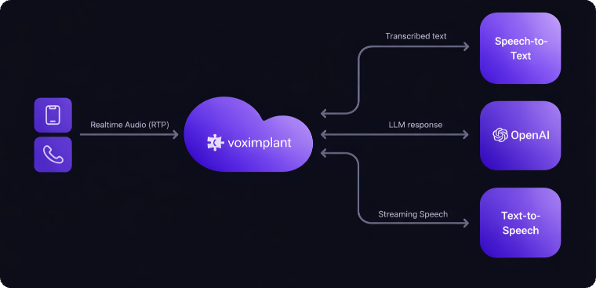
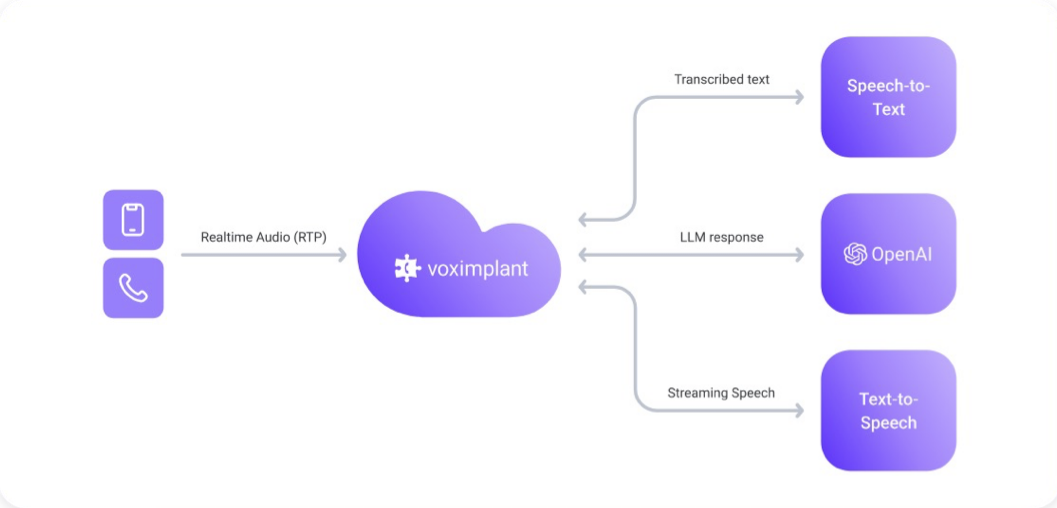
Separate STT, LLM, and TTS stages for maximum provider flexibility and pipeline control.
Most configurable | Most complex
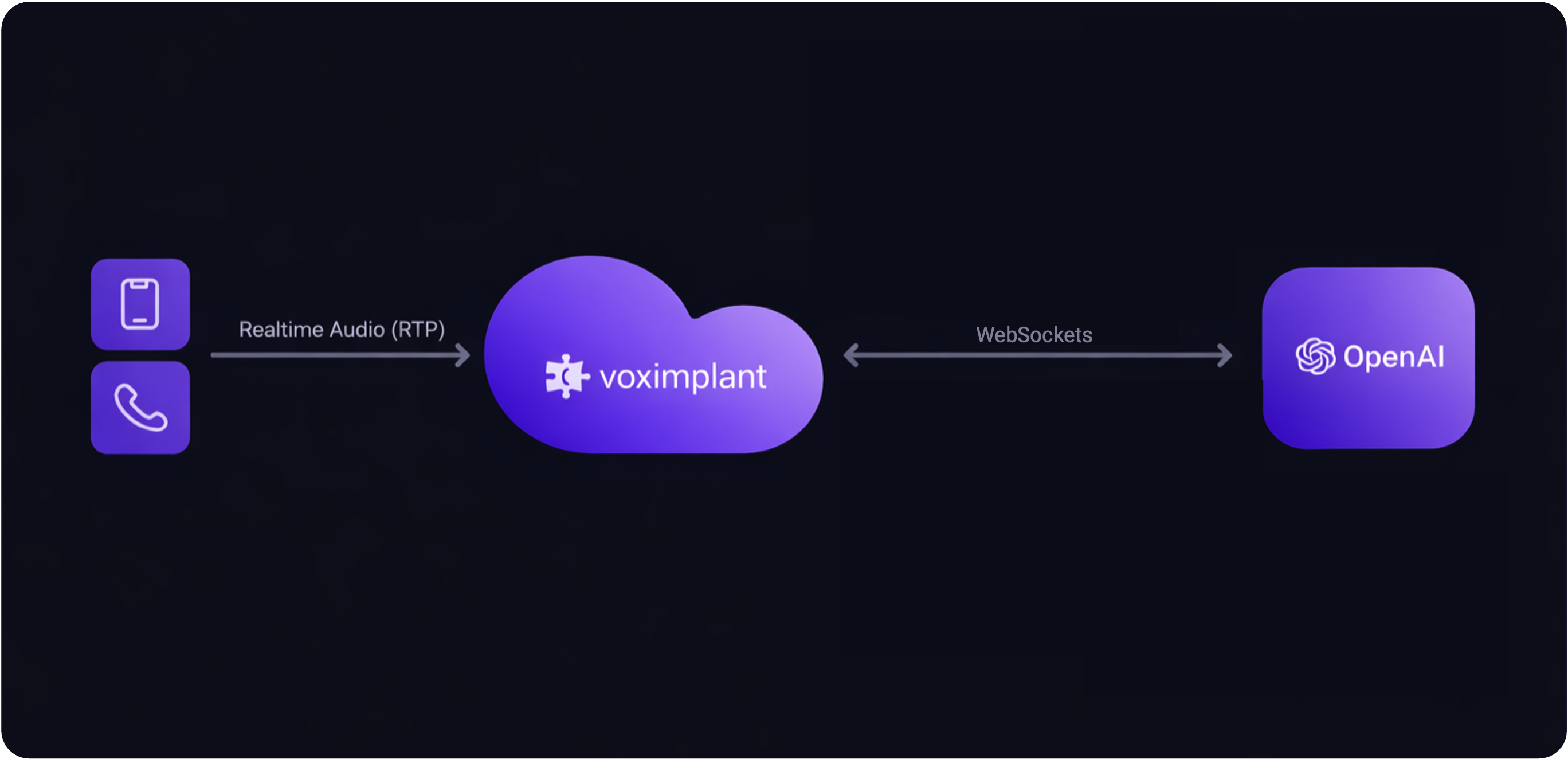
Direct realtime speech-to-speech with OpenAI.
Direct live audio pipeline with Gemini Live.
Realtime voice interaction with Grok voice agent sessions.
Speech-native realtime agent with native speech input and output.
Conversational agent sessions with realtime speech handling.
Realtime voice agent flow with Deepgram speech input and output.
Speech-to-speech agent flow with Cartesia-managed runtime behavior.
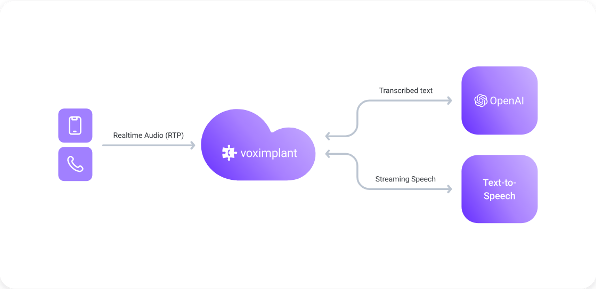
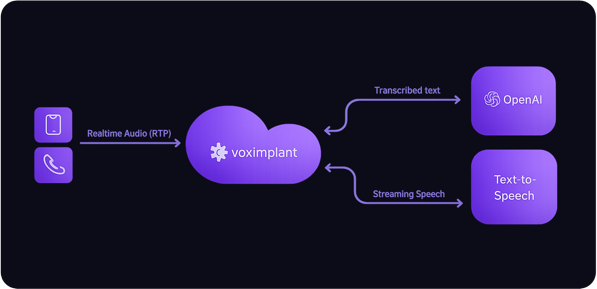
Realtime LLM with Cartesia realtime TTS.
Realtime LLM with ElevenLabs streaming TTS.
Realtime LLM with Inworld speech output.