Pipeline Options
For the complete documentation index, see llms.txt.
VoxEngine supports a wide variety of Voice AI architectures and components. The right pipeline depends on your priorities — low latency, interactivity needs, voice choice, and low-level control are some factors to consider.
User↔LLM
Speech-to-speech (S2S)
Fully integrated Voice AI that often offers the lowest overall latency.
Fastest path | Lowest latencyLLM↔TTS
Hybrid-cascade
Realtime LLM for speech input and reasoning, with a separate TTS system for output voice.
More voice choice | Still realtimeSTT↔LLM↔TTS
Cascaded
Separate STT, LLM, and TTS stages for maximum provider flexibility and pipeline control.
Most configurable | Most complexHigh-level comparison
Some vendors present a speech-to-speech (S2S) API externally, but internally manage a cascaded architecture with separate components with varying degrees of control and configuration. See more details below.
- Start with speech-to-speech when you want to get to a working voice agent quickly.
- Move to hybrid-cascade when you need more TTS voice choices and control, and can tolerate some additional latency.
- Consider full cascade when you need independent control over transcription, reasoning, playback, turn-taking, or provider mix and are willing to manage the additional interactions.
Voximplant Connectors & Pipeline Support
Voximplant always manages the telephony side of the call: routing, answering, bridging media, call control, and any orchestration logic you add in VoxEngine. Our Voice AI API clients - also referred to as connectors - provide a direct connection from VoxEngine to the provider’s environment with a low-latency WebSocket connection. Voximplant’s various connector options differ in how they handle transcription, reasoning, and speech synthesis internally.
LLMs like OpenAI, Gemini, and Grok provide direct access to the speech-enabled LLM. Speech input and output parameters are managed as part of the connector.
Ultravox provides a speech-native LLM, but integrates TTS within their environment, only exposing a Speech-to-Speech interface to Voximplant. Similarly, ElevenLabs, Cartesia, and Deepgram provide a speech-to-speech interface to Voximplant, but handle LLM, STT, and TTS elements internally. Configuration of these internal elements vary by vendor. We refer to the integrations as “indirect speech-to-speech”.
All vendors provide some level of end-of-turn detection, with some vendors providing more explicit control over turn-taking and barge-in.
The table below summarizes support by vendor from the Voximplant connector perspective.
Speech-to-speech
In this pattern, caller audio is bridged to the provider in realtime, and the provider returns speech audio directly back into the call.
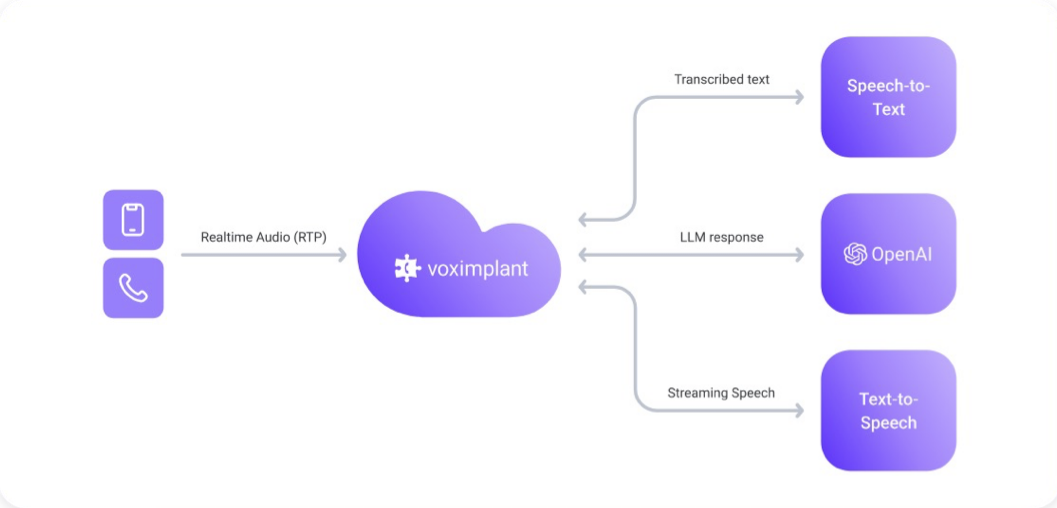
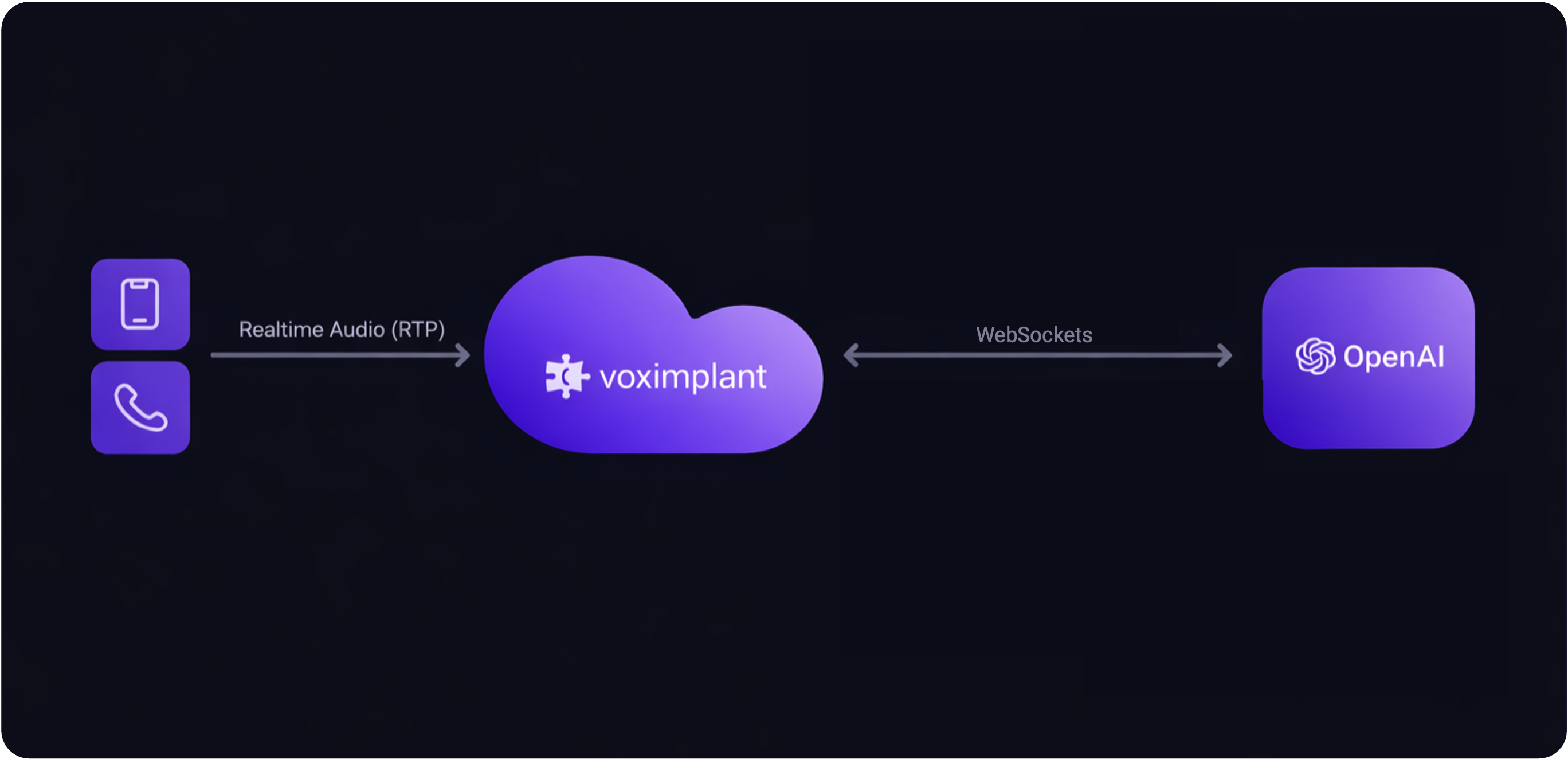
How it works
- Caller audio is streamed from VoxEngine to a realtime voice agent over WebSockets.
- The provider handles speech recognition, reasoning, and speech generation in one session.
- VoxEngine manages telephony, routing, media bridge, and call control around that session.
Tradeoffs
Advantages
- Lowest end-to-end latency.
- Simple architecture with fewer systems to coordinate.
- Fastest path from prototype to production trial.
- Natural fit for direct realtime connectors with built-in streaming speech.
Disadvantages
- Voice quality and speech style are limited to the provider’s native output voices.
- You have less control over how STT, reasoning, and speech output are separated.
- Switching one stage often means switching the whole stack.
Best for
- You want the fastest possible conversational loop.
- You are happy with the provider’s built-in voices.
- You want the simplest operational model.
Related guides
Direct speech-to-speech connectors
These connectors expose the speech-enabled LLM directly to VoxEngine.
OpenAI
Direct realtime speech-to-speech with OpenAI.
Gemini Live
Direct live audio pipeline with Gemini Live.
xAI Grok Voice Agent
Realtime voice interaction with Grok voice agent sessions.
Indirect speech-to-speech connectors
These connectors present a speech-to-speech interface to VoxEngine while managing more of the internal speech and agent stack inside the provider environment.
Ultravox
Speech-native realtime agent with native speech input and output.
ElevenLabs Agents
Conversational agent sessions with realtime speech handling.
Deepgram Agents
Realtime voice agent flow with Deepgram speech input and output.
Cartesia Line Agents
Speech-to-speech agent flow with Cartesia-managed runtime behavior.
Hybrid-cascade
Hybrid-cascade - sometimes called half-cascade - keeps the realtime LLM in the loop for user speech input and reasoning, but moves speech output to a separate synthesis provider. This is often the best compromise between latency and voice flexibility.
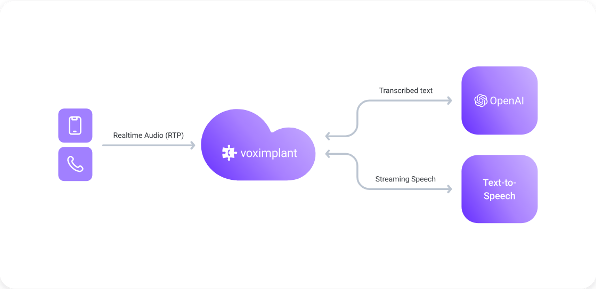
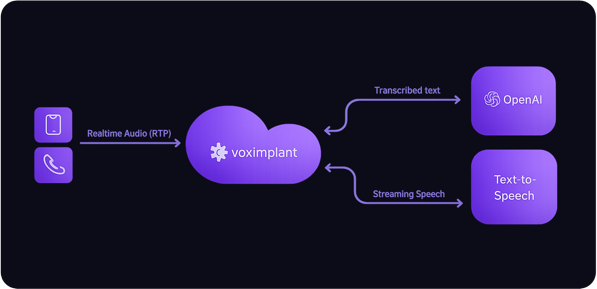
How it works
- Caller audio is streamed to a realtime LLM.
- The realtime LLM returns text rather than audio (or you transcribe the audio).
- VoxEngine sends the text into a TTS engine and streams the generated speech back to the caller.
Tradeoffs
Advantages
- Much broader choice of output voices and TTS providers.
- Lets you tune speaking style, voice identity, and output pricing separately from the LLM.
- Still supports low-latency streaming when paired with realtime TTS.
- Good balance between orchestration control and implementation simplicity.
Disadvantages
- More moving parts than direct speech-to-speech.
- Output latency depends on the selected TTS provider and playback strategy.
- Increased cost - you need to pay for realtime LLM and speech synthesis.
Best for
- You want a specific voice provider or voice quality that your LLM provider does not offer.
- You want more control over output speech without moving to a full cascade.
- You need a practical middle ground between speed and flexibility.
Related guides
OpenAI + Cartesia
Realtime LLM with Cartesia realtime TTS.
OpenAI + ElevenLabs
Realtime LLM with ElevenLabs streaming TTS.
OpenAI + Inworld
Realtime LLM with Inworld speech output.
Full cascade
Full cascade separates speech-to-text, reasoning, and text-to-speech into independent stages. This gives you the most control over the pipeline and the most freedom to mix providers.
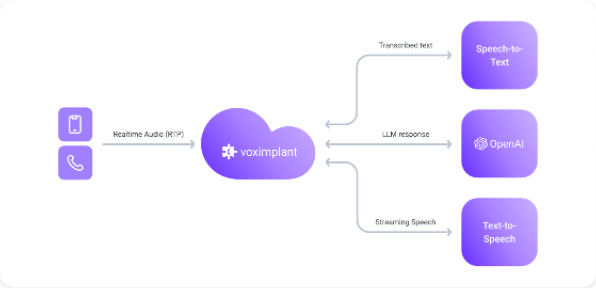
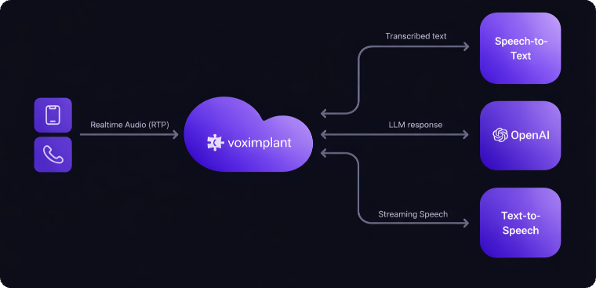
How it works
- VoxEngine transcribes caller audio with an STT integration.
- Your scenario sends text to an LLM or OpenAI-compatible endpoint.
- The text response is synthesized through a TTS provider and streamed back into the call.
- Voice activity detection, turn detection, and barge-in control are handled explicitly in the orchestration layer.
Tradeoffs
Advantages
- Maximum freedom to choose the best STT, LLM, and TTS provider for each stage.
- Strong control over turn-taking, interruption logic, and prompt/response handling.
- Works well when you need custom transcription behavior, domain vocabulary, or provider-specific tuning.
- Easier to swap one layer without redesigning the whole pipeline.
Disadvantages
- Highest implementation and operational complexity.
- More places to manage latency and streaming coordination.
- Requires deliberate turn-taking and barge-in handling for a natural caller experience.
Best for
- You need full control over transcription, reasoning, and speech generation.
- You want to mix providers based on quality, language support, or cost.
- You need explicit turn-taking logic or custom orchestration around the LLM.
Related guides
For turn-taking, interruption, and end-of-turn behavior, see the Speech Flow Control guides.
Responses: Deepgram-Groq-Inworld
Independent STT, LLM, and TTS with explicit turn-taking.
Turn Taking Helper Library
Reference guide for VAD, turn detection, and barge-in orchestration.
Run TTS in VoxEngine
Related guide for playback and TTS orchestration patterns.
Choosing a pipeline
If you are new to Voice AI starting from scratch, we recommend the following progression:
- Start with speech-to-speech to validate the call flow and prompt design quickly.
- Move to hybrid-cascade if you need a different voice or output speech behavior than your speech-LLM provider offers.
- Move to full cascade when you need full provider selection, explicit turn-taking control, and/or custom orchestration between stages.
That progression keeps the first version simple while leaving room to add flexibility only when the product requirements justify the extra moving parts.